【深入解读】机器学习预测高温合金蠕变断裂寿命
2020-07-26 来源:Goal Science
从本期开始,我们将尝试不定期选取部分国际权威期刊近期发表的金属领域相关论文,在介绍研究成果的同时,也提供一些学术观点共各位读者批判和讨论,希望能帮助大家更好地了解学术前沿的热点难点,起到抛砖引玉的作用。非常欢迎各位读者在评论区分享自己的观点,或对栏目提出宝贵意见。
论文速读
蠕变是合金在高温服役时最重要的性能参数之一。然而,蠕变性能的实验测量却是十分耗时且昂贵的,一个实验样本点的获取往往就需要几千甚至几万小时,消耗的科研经费以万计。得益于近年来数据科学的快速发展,越来越多的研究者开始尝试通过机器学习的方法对合金的蠕变性能进行预测。
近日,来自上海大学、清华大学、钢铁研究总院等多个单位的合作团队在Acta Materialia发表了其在利用机器学习方法预测镍基单晶高温合金蠕变性能方面取得的最新进展。模型训练集共涵盖镍基单晶高温合金的266组数据样本,除了成分和热处理工艺等22组基础特征以外,研究团队还引入了层错能、扩散系数、剪切模量、晶格常数、γ'相分数等5组额外的物理特征作为模型输入。这些物理特征可以通过Thermo-calc结合物理唯象模型获取。与其他文献中已发表的用于预测材料蠕变性能的机器学习模型不同的是,该模型在运行的初始阶段引入了一步无监督聚类算法,将266组数据分为8个子类。使用支持向量机、随机森林、高斯回归等5种算法对每个子类中的数据进行单独训练,选择其中效果最好的算法作为该子类的算法,最终使得模型对整体数据的预测性能大幅提高。
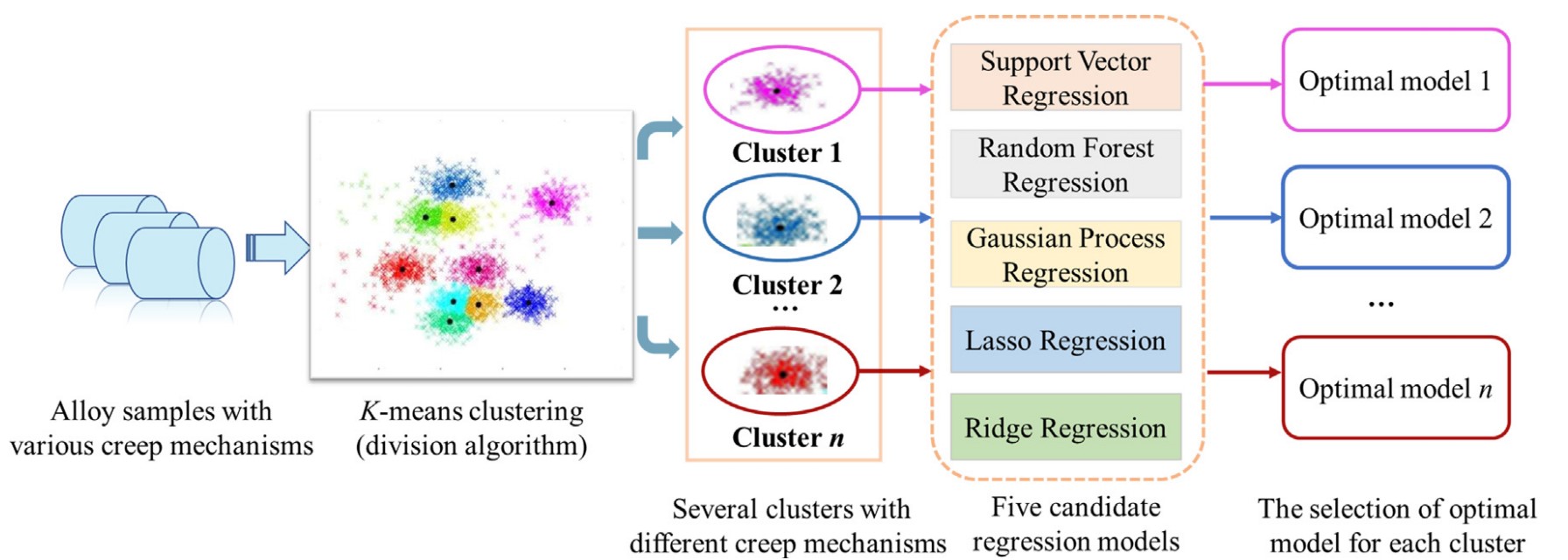
图1 机器学习模型流程图
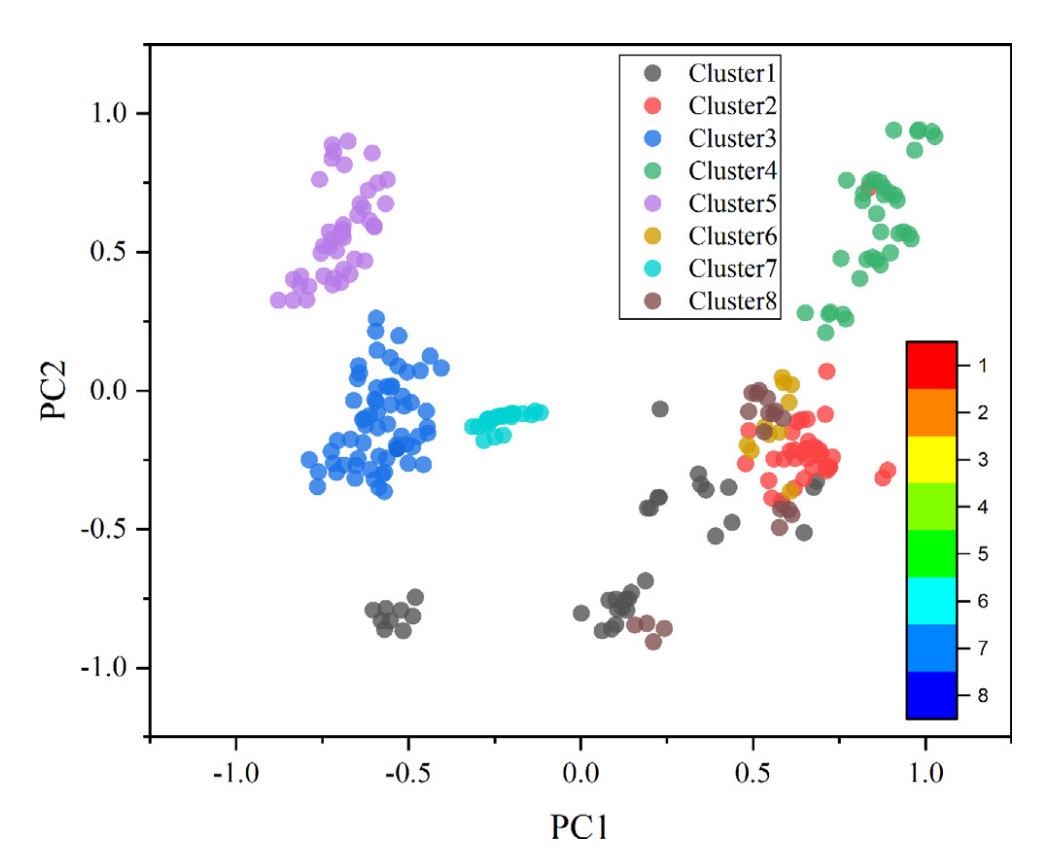
图2 样本聚类后在二维平面的投影
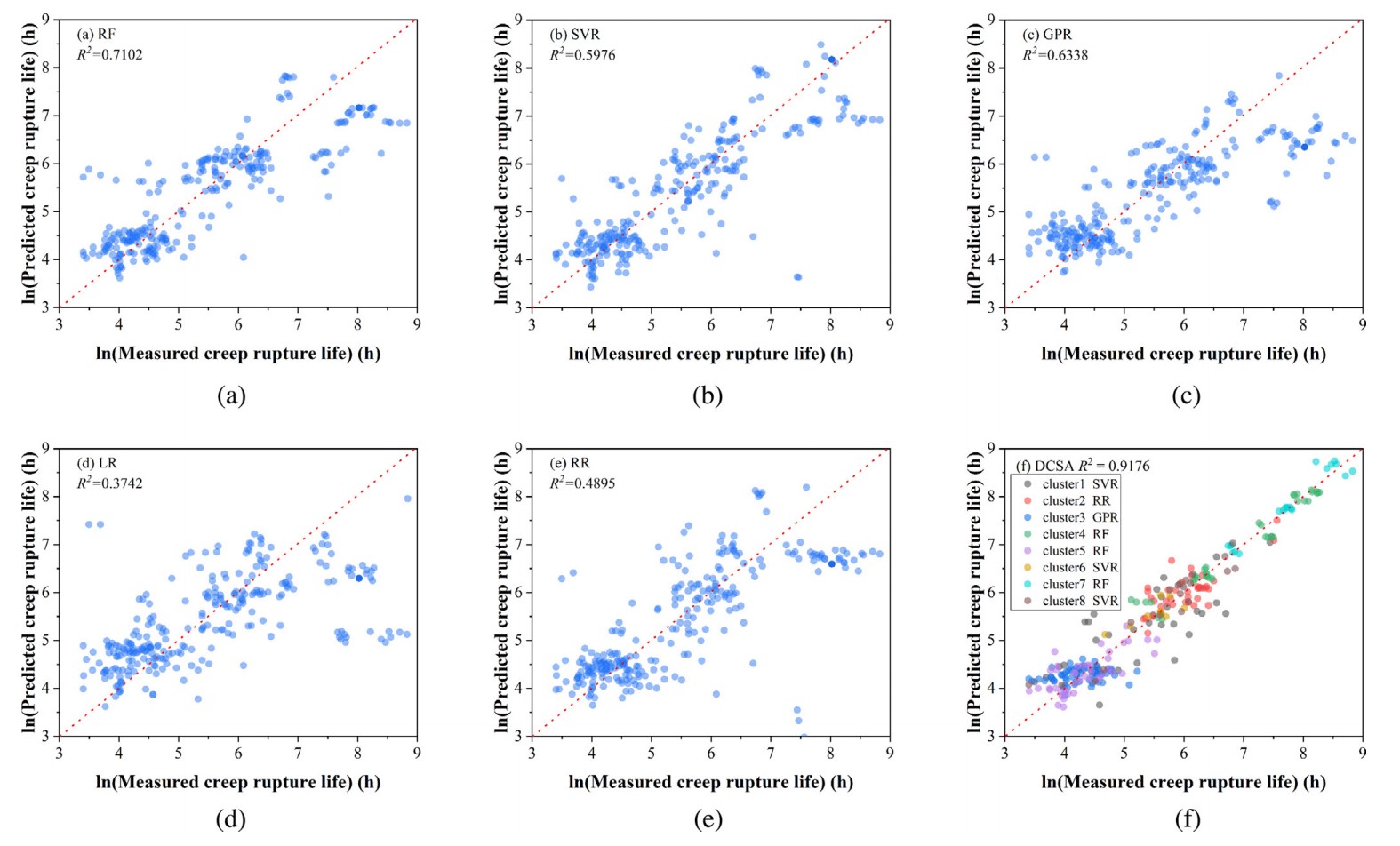
图3 “分治”模型和其他5种模型的性能对比
观点评述
近年来,在国际权威期刊上越来越多地开始出现机器学习在材料领域应用的相关文章。这一方面是由于人工智能的高热度,另一方面也意味着在计算机科学与材料科学的交叉领域,还有大量值得探索的学术荒地。而其中,利用机器学习预测蠕变性能又是特别有意义的,因为蠕变实验所需花费的时间和财力成本通常远非其他实验可比。长久以来,机器学习在合金蠕变性能预测方面的挑战主要集中在以下几个方面:
(1)蠕变性能的已有数据相对较少,因此这是一个稀疏数据集上的训练问题,模型必须一方面避免对已有数据的过拟合,同时尽可能地提高模型的泛化能力。
(2)机器学习的过程往往是一个黑箱,如何将模型与实际的物理过程建立联系,从而基于模型预测结果启发或加深对实际过程物理图像的理解,这是材料科学家相比于传统的计算机科学家更关心的问题。
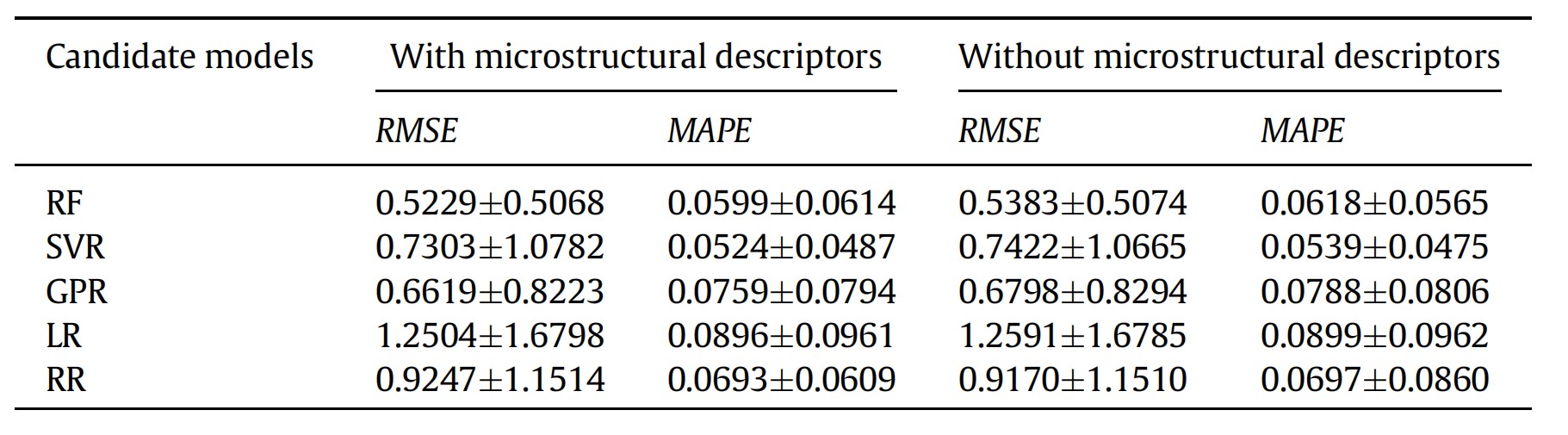
最近在Acta Materialia上发表的这项研究,是一项十分具有启发性的工作,首先最显而易见的亮点自然是模型成功地大幅提高了预测性能。此外,针对我们之前提到的两点挑战,研究团队也提供了一些有益的尝试。比如说,引入层错能等具有物理意义的特征作为模型的输入,就是可能的,也是目前较为常见的,利用机器学习揭示影响材料蠕变性能的物理参数的手段之一。这种发法并非本文的研究团队首创,此前已有团队将Thermo-calc热力学软件中的计算结果直接作为机器学习模型的输入。但值得一提的是,本文的研究团队在此基础之上更进了一步,将热力学软件计算结果(如原子占位分数等)首先带入了感兴趣的,同时也可能是对蠕变性能有重要影响的物理量的有关公式,随后再将计算结果带入模型。因此,从某种意义上来说,这一模型更多地融入了前人对材料物理机制的认识。但是很遗憾地,结果并不理想。在此,我们引用文章中的一张表格(见表1)。该表格中的数据结果表明,只使用22组基本特征(主要包括成分和工艺参数)和额外引入5组物理特征作为输入后,模型的性能并未出现显著差异。这与19年Acta上表发的另一篇利用机器学习预测合金蠕变性能的文章Modern data analytics approach to predict creep of high-temperature alloys 中的结论一致。因此,在通过向机器学习模型中引入具有物理意义的特征作为输入,以此揭示材料蠕变机理这条道路上,研究者可能还需要更多的思考和尝试。至少就目前来说,我们甚至不知道,这种方法是否真的有效。
表1 模型输入特征的选择对模型性能的影响

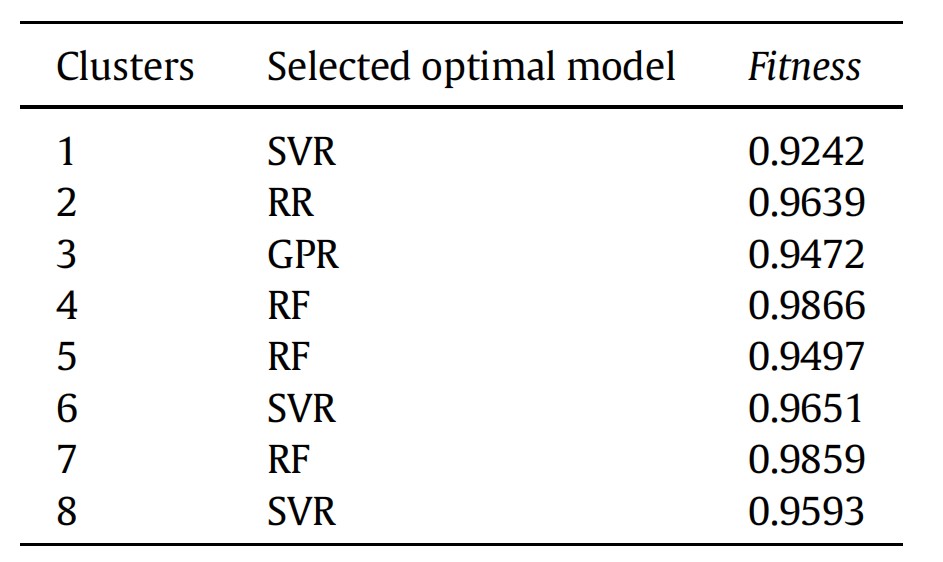
另外,在本研究中,作者首先对266组数据点进行了无监督聚类,随后每个子类都通过训练,选择了RF, SVR, GPR, LR和RR这5种算法中的最佳算法,因此模型在整体数据集上的性能提高是可以预见的。事实上,这种所谓的“分而治之”(divide-and-conquer)机器学习模型最大优势之一,是可以通过少量的训练,快速地在子类和算法之间建立联系,从而在面对大数据集时,越过中间的算法选择环节,节约大量算力。因此从数据科学的角度来说,模型的优势在面对蠕变性能预测这样的稀疏问题上尚未得到充分发挥。但对于材料科学家而言重要的是,研究团队发现无监督聚类的结果在一定程度上反应了镍基单晶高温合金的代际特征,且不同子类对应不同的算法选择(见表2)。这反映聚类算法这种对相似性的度量具有一定的物理意义。不同的算法对应也可能是各个子类镍基单晶高温合金蠕变机制不同的一种暗示,虽然就目前而言证据还远远不足,但这种挖掘机器学习模型与材料物理机制尝试在现阶段已经是非常有意义的了。
表2 不同数据子类对应的算法
欢迎留言,材料科学的进步,需要您的发声!
原文链接: